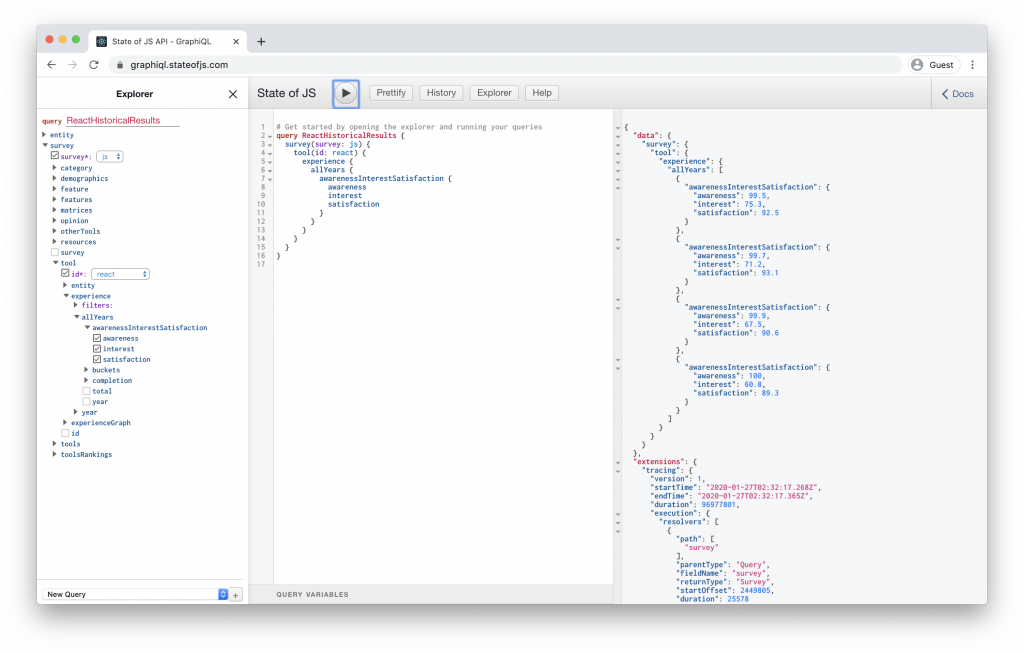
If you haven’t worked with immutability in JavaScript before, you might find it easy to confuse it with assigning a variable to a new value, or reassignment. While it’s possible to reassign variables and values declared using let or var, you'll begin to run into issues when you try that with const.
Say we assign the value Kingsley to a variable called firstName:
let firstName = "Kingsley";
We can reassign a new value to the same variable,
firstName = "John";
This is possible because we used let. If we happen to use const instead like this:
const lastName = "Silas";
…we will get an error when we try to assign it to a new value;
lastName = "Doe"
// TypeError: Assignment to constant variable.
That is not immutability.
An important concept you’ll hear working with a framework, like React, is that mutating states is a bad idea. The same applies to props. Yet, it is important to know that immutability is not a React concept. React happens to make use of the idea of immutability when working with things like state and props.
What the heck does that mean? That’s where we're going to pick things up.
Mutability is about sticking to the facts
Immutable data cannot change its structure or the data in it. It’s setting a value on a variable that cannot change, making that value a fact, or sort of like a source of truth — the same way a princess kisses a frog hoping it will turn into a handsome prince. Immutability says that frog will always be a frog.
[ILLUSTRATION]
Objects and arrays, on the other hand, allow mutation, meaning the data structure can be changed. Kissing either of those frogs may indeed result in the transformation of a prince if we tell it to.
[ILLUSTRATION]
Say we have a user object like this:
let user = { name: "James Doe", location: "Lagos" }
Next, let’s attempt to create a newUser object using those properties:
let newUser = user
Now let’s imagine the first user changes location. It will directly mutate the user object and affect the newUser as well:
user.location = "Abia"
console.log(newUser.location) // "Abia"
This might not be what we want. You can see how this sort of reassignment could cause unintended consequences.
Working with immutable objects
We want to make sure that our object isn’t mutated. If we’re going to make use of a method, it has to return a new object. In essence, we need something called a pure function.
A pure function has two properties that make it unique:
- The value it returns is dependent on the input passed. The returned value will not change as long as the inputs do not change.
- It does not change things outside of its scope.
By using Object.assign(), we can create a function that does not mutate the object passed to it. This will generate a new object instead by copying the second and third parameters into the empty object passed as the first parameter. Then the new object is returned.
const updateLocation = (data, newLocation) => {
return {
Object.assign({}, data, {
location: newLocation
})
}
}
updateLocation() is a pure function. If we pass in the first user object, it returns a new user object with a new value for the location.
Another way to go is using the Spread operator:
const updateLocation = (data, newLocation) => {
return {
...data,
location: newLocation
}
}
OK, so how does this all of this fit into React? Let’s get into that next.
Immutability in React
In a typical React application, the state is an object. (Redux makes use of an immutable object as the basis of an application’s store.) React’s reconciliation process determines if a component should re-render or if it needs a way to keep track of the changes.
In other words, if React can’t figure out that the state of a component has changed, then it will not not know to update the Virtual DOM.
Immutability, when enforced, makes it possible to keep track of those changes. This allows React to compare the old state if an object with it’s new state and re-render the component based on that difference.
This is why directly updating state in React is often discouraged:
this.state.username = "jamesdoe";
React will not be sure that the state has changed and is unable to re-render the component.
Immutable.js
Redux adheres to the principles of immutability. Its reducers are meant to be pure functions and, as such, they should not mutate the current state but return a new object based on the current state and action. We’d typically make use of the spread operator like we did earlier, yet it is possible to achieve the same using a library called Immutable.js.
While plain JavaScript can handle immutability, it’s possible to run into a handful of pitfalls along the way. Using Immutable.js guarantees immutability while providing a rich API that is big on performance. We won’t be going into all of the fine details of Immutability.js in this piece, but we will look at a quick example that demonstrates using it in a to-do application powered by React and Redux.
First, lets’ start by importing the modules we need and set up the Todo component while we’re at it.
const { List, Map } = Immutable;
const { Provider, connect } = ReactRedux;
const { createStore } = Redux;
If you are following along on your local machine. you’ll need to have these packages installed:
npm install redux react-redux immutable
The import statements will look like this.
import { List, Map } from "immutable";
import { Provider, connect } from "react-redux";
import { createStore } from "redux";
We can then go on to set up our Todo component with some markup:
const Todo = ({ todos, handleNewTodo }) => {
const handleSubmit = event => {
const text = event.target.value;
if (event.which === 13 && text.length > 0) {
handleNewTodo(text);
event.target.value = "";
}
};
return (
<section className="section">
<div className="box field">
<label className="label">Todo</label>
<div className="control">
<input
type="text"
className="input"
placeholder="Add todo"
onKeyDown={handleSubmit}
/>
</div>
</div>
<ul>
{todos.map(item => (
<div key={item.get("id")} className="box">
{item.get("text")}
</div>
))}
</ul>
</section>
);
};
We’re using the handleSubmit() method to create new to-do items. For the purpose of this example, the user will only be create new to-do items and we only need one action for that:
const actions = {
handleNewTodo(text) {
return {
type: "ADD_TODO",
payload: {
id: uuid.v4(),
text
}
};
}
};
The payload we’re creating contains the ID and the text of the to-do item. We can then go on to set up our reducer function and pass the action we created above to the reducer function:
const reducer = function(state = List(), action) {
switch (action.type) {
case "ADD_TODO":
return state.push(Map(action.payload));
default:
return state;
}
};
We’re going to make use of connect to create a container component so that we can plug into the store. Then we’ll need to pass in mapStateToProps() and mapDispatchToProps() functions to connect.
const mapStateToProps = state => {
return {
todos: state
};
};
const mapDispatchToProps = dispatch => {
return {
handleNewTodo: text => dispatch(actions.handleNewTodo(text))
};
};
const store = createStore(reducer);
const App = connect(
mapStateToProps,
mapDispatchToProps
)(Todo);
const rootElement = document.getElementById("root");
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
rootElement
);
We’re making use of mapStateToProps() to supply the component with the store’s data. Then we’re using mapDispatchToProps() to make the action creators available as props to the component by binding the action to it.
In the reducer function, we make use of List from Immutable.js to create the initial state of the app.
const reducer = function(state = List(), action) {
switch (action.type) {
case "ADD_TODO":
return state.push(Map(action.payload));
default:
return state;
}
};
Think of List as a JavaScript array, which is why we can make use of the .push() method on state. The value used to update state is an object that goes on to say that Map can be recognized as an object. This way, there’s no need to use Object.assign() or the spread operator, as this guarantees that the current state cannot change. This looks a lot cleaner, especially if it turns out that the state is deeply nested — we do not need to have spread operators sprinkled all over
Immutable states make it possible for code to quickly determine if a change has occurred. We do not need to do a recursive comparison on the data to determine if a change happened. That said, it’s important to mention that you might run into performance issues when working with large data structures — there’s a price that comes with copying large data objects.
But data needs to change because there’s otherwise no need for dynamic sites or applications. The important thing is how the data is changed. Immutability provides the right way to change the data (or state) of an application. This makes it possible to trace the state’s changes and determine what the parts of the application should re-render as a result of that change.
Learning about immutability the first time will be confusing. But you’ll become better as you bump into errors that pop up when the state is mutated. That’s often the clearest way to understand the need and benefits of immutability.
Further reading
The post Understanding Immutability in JavaScript appeared first on CSS-Tricks.
from CSS-Tricks https://ift.tt/36GdsPY
via
IFTTT

 which seems pretty far when you put it that way, but from up here on Earth it's practically all the way down.")