JavaScript has a variety of built-in popup APIs that display special UI for user interaction. Famously:
alert("Hello, World!");
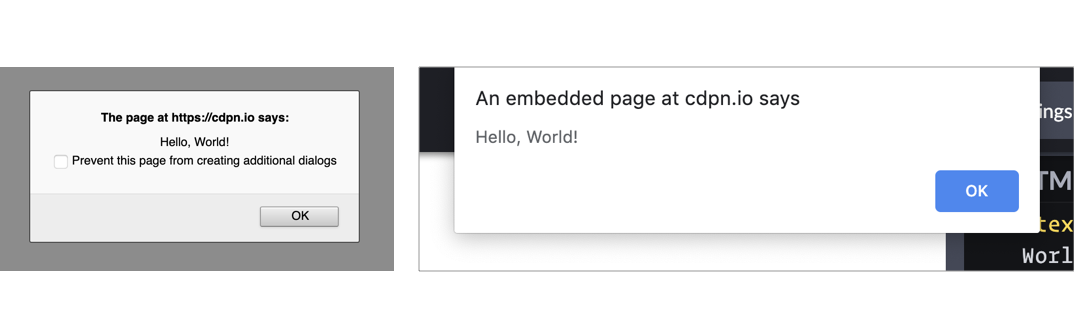
The UI for this varies from browser to browser, but generally you’ll see a little window pop up front and center in a very show-stopping way that contains the message you just passed. Here’s Firefox and Chrome:
Native popups in Firefox (left) and Chrome (right). Note the additional UI preventing additional dialogs in Firefox from triggering it more than once. You can also see how Chrome is pinned to the top of the window.
There is one big problem you should know about up front
JavaScript popups are blocking.
The entire page essentially stops when a popup is open. You can’t interact with anything on the page while one is open — that’s kind of the point of a “modal” but it’s still a UX consideration you should be keenly aware of. And crucially, no other main-thread JavaScript is running while the popup is open, which could (and probably is) unnecessarily preventing your site from doing things it needs to do.
Nine times out of ten, you’d be better off architecting things so that you don’t have to use such heavy-handed stop-everything behavior. Native JavaScript alerts are also implemented by browsers in such a way that you have zero design control. You can’t control *where* they appear on the page or what they look like when they get there. Unless you absolutely need the complete blocking nature of them, it’s almost always better to use a custom user interface that you can design to tailor the experience for the user.
With that out of the way, let’s look at each one of the native popups.
What it’s for: Displaying a simple message or debugging the value of a variable.
How it works: This function takes a string and presents it to the user in a popup with a button with an “OK” label. You can only change the message and not any other aspect, like what the button says.
The Alternative: Like the other alerts, if you have to present a message to the user, it’s probably better to do it in a way that’s tailor-made for what you’re trying to do.
If you’re trying to debug the value of a variable, consider console.log(<code>"`Value of variable:"`, variable); and looking in the console.
window.confirm();
window.confirm("Are you sure?");
<button onclick="confirm('Would you like to play a game?');">Ask Question</button>
let answer = window.confirm("Do you like cats?");
if (answer) {
// User clicked OK
} else {
// User clicked Cancel
}
What it’s for: “Are you sure?”-style messages to see if the user really wants to complete the action they’ve initiated.
How it works: You can provide a custom message and popup will give you the option of “OK” or “Cancel,” a value you can then use to see what was returned.
The Alternative: This is a very intrusive way to prompt the user. As Aza Raskin puts it:
...maybe you don’t want to use a warning at all.”
There are any number of ways to ask a user to confirm something. Probably a clear UI with a <button>Confirm</button> wired up to do what you need it to do.
window.prompt();
window.prompt("What’s your name?");
let answer = window.prompt("What is your favorite color?");
// answer is what the user typed in, if anything
What it’s for: Prompting the user for an input. You provide a string (probably formatted like a question) and the user sees a popup with that string, an input they can type into, and “OK” and “Cancel” buttons.
How it works: If the user clicks OK, you’ll get what they entered into the input. If they enter nothing and click OK, you’ll get an empty string. If they choose Cancel, the return value will be null.
The Alternative: Like all of the other native JavaScript alerts, this doesn’t allow you to style or position the alert box. It’s probably better to use a <form> to get information from the user. That way you can provide more context and purposeful design.
window.onbeforeunload();
window.addEventListener("beforeunload", () => {
// Standard requires the default to be cancelled.
event.preventDefault();
// Chrome requires returnValue to be set (via MDN)
event.returnValue = '';
});
What it’s for: Warn the user before they leave the page. That sounds like it could be very obnoxious, but it isn’t often used obnoxiously. It’s used on sites where you can be doing work and need to explicitly save it. If the user hasn’t saved their work and is about to navigate away, you can use this to warn them. If they *have* saved their work, you should remove it.
How it works: If you’ve attached the beforeunload event to the window (and done the extra things as shown in the snippet above), users will see a popup asking them to confirm if they would like to “Leave” or “Cancel” when attempting to leave the page. Leaving the site may be because the user clicked a link, but it could also be the result of clicking the browser’s refresh or back buttons. You cannot customize the message.
MDN warns that some browsers require the page to be interacted with for it to work at all:
To combat unwanted pop-ups, some browsers don't display prompts created in beforeunload event handlers unless the page has been interacted with. Moreover, some don't display them at all.
The Alternative: Nothing that comes to mind. If this is a matter of a user losing work or not, you kinda have to use this. And if they choose to stay, you should be clear about what they should to to make sure it’s safe to leave.
Accessibility
Native JavaScript alerts used to be frowned upon in the accessibility world, but it seems that screen readers have since become smarter in how they deal with them. According to Penn State Accessibility:
The use of an alert box was once discouraged, but they are actually accessible in modern screen readers.
It’s important to take accessibility into account when making your own modals, but there are some great resources like this post by Ire Aderinokun to point you in the right direction.
General alternatives
There are a number of alternatives to native JavaScript popups such as writing your own, using modal window libraries, and using alert libraries. Keep in mind that nothing we’ve covered can fully block JavaScript execution and user interaction, but some can come close by greying out the background and forcing the user to interact with the modal before moving forward.
You may want to look at HTML’s native <dialog> element. Chris recently took a hands-on look) at it. It’s compelling, but apparently suffers from some significant accessibility issues. I’m not entirely sure if building your own would end up better or worse, since handling modals is an extremely non-trivial interactive element to dabble in. Some UI libraries, like Bootstrap, offer modals but the accessibility is still largely in your hands. You might to peek at projects like a11y-dialog.
Wrapping up
Using built-in APIs of the web platform can seem like you’re doing the right thing — instead of shipping buckets of JavaScript to replicate things, you’re using what we already have built-in. But there are serious limitations, UX concerns, and performance considerations at play here, none of which land particularly in favor of using the native JavaScript popups. It’s important to know what they are and how they can be used, but you probably won’t need them a heck of a lot in production web sites.
Indie and enterprise web developers alike are pushing toward a serverless architecture for modern applications. Serverless architectures typically scale well, avoid the need for server provisioning and most importantly are easy and cheap to set up! And that’s why I believe the next evolution for cloud is serverless because it enables developers to focus on writing applications.
With that in mind, let’s build a REST API (because will we ever stop making these?) using 100% serverless technology.
We’re going to do that with Firebase Cloud Functions and FaunaDB, a globally distributed serverless database with native GraphQL.
Those familiar with Firebase know that Google’s serverless app-building tools also provide multiple data storage options: Firebase Realtime Database and Cloud Firestore. Both are valid alternatives to FaunaDB and are effectively serverless.
But why choose FaunaDB when Firestore offers a similar promise and is available with Google’s toolkit? Since our application is quite simple, it does not matter that much. The main difference is that once my application grows and I add multiple collections, then FaunaDB still offers consistency over multiple collections whereas Firestore does not. In this case, I made my choice based on a few other nifty benefits of FaunaDB, which you will discover as you read along — and FaunaDB’s generous free tier doesn’t hurt, either. 😉
In this post, we’ll cover:
Installing Firebase CLI tools
Creating a Firebase project with Hosting and Cloud Function capabilities
Routing URLs to Cloud Functions
Building three REST API calls with Express
Establishing a FaunaDB Collection to track your (my) favorite video games
Creating FaunaDB Documents, accessing them with FaunaDB’s JavaScript client API, and performing basic and intermediate-level queries
And more, of course!
Set Up A Local Firebase Functions Project
For this step, you’ll need Node v8 or higher. Install firebase-tools globally on your machine:
$ npm i -g firebase-tools
Then log into Firebase with this command:
$ firebase login
Make a new directory for your project, e.g. mkdir serverless-rest-api and navigate inside.
Create a Firebase project in your new directory by executing firebase login.
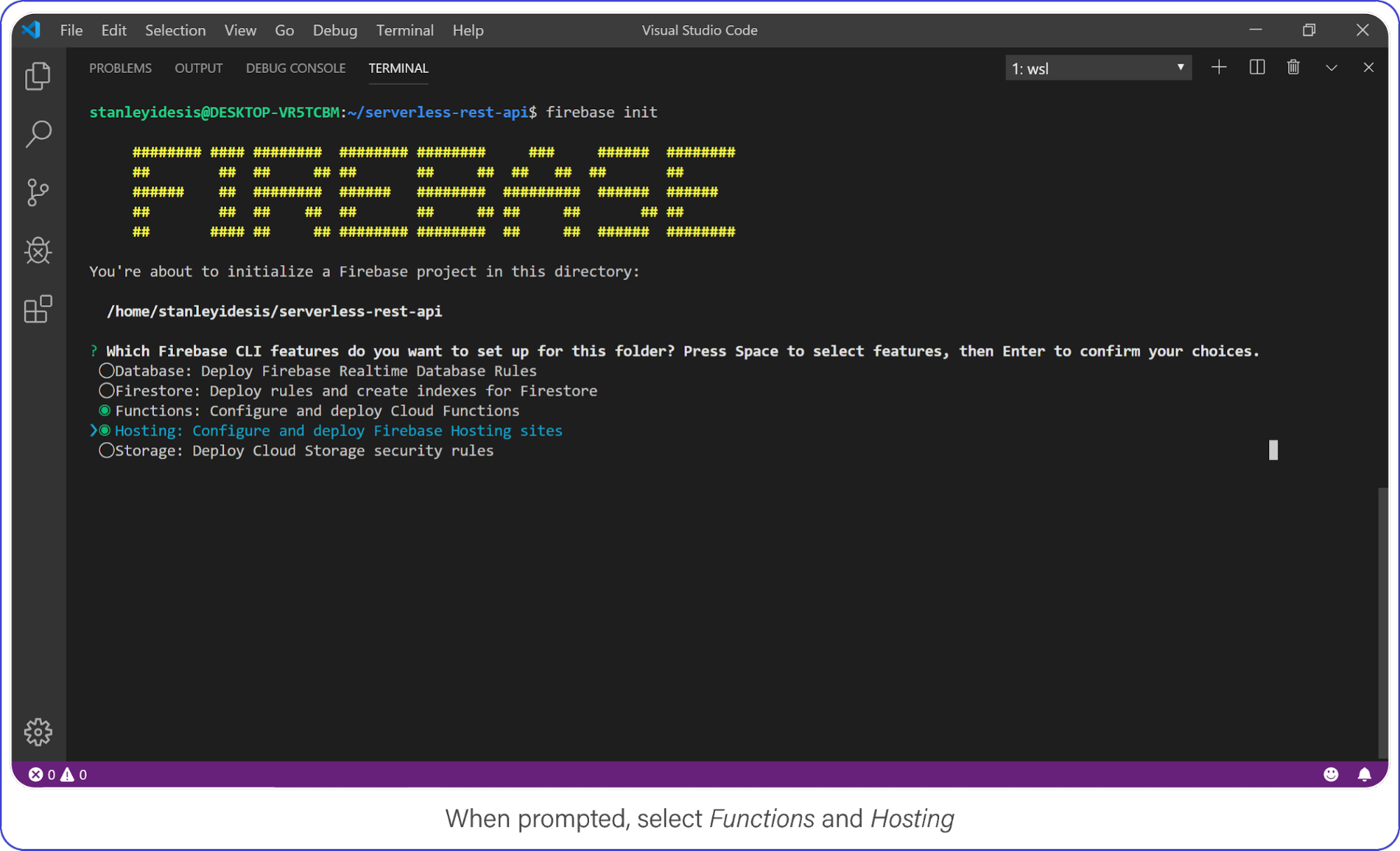
Select Functions and Hosting when prompted.
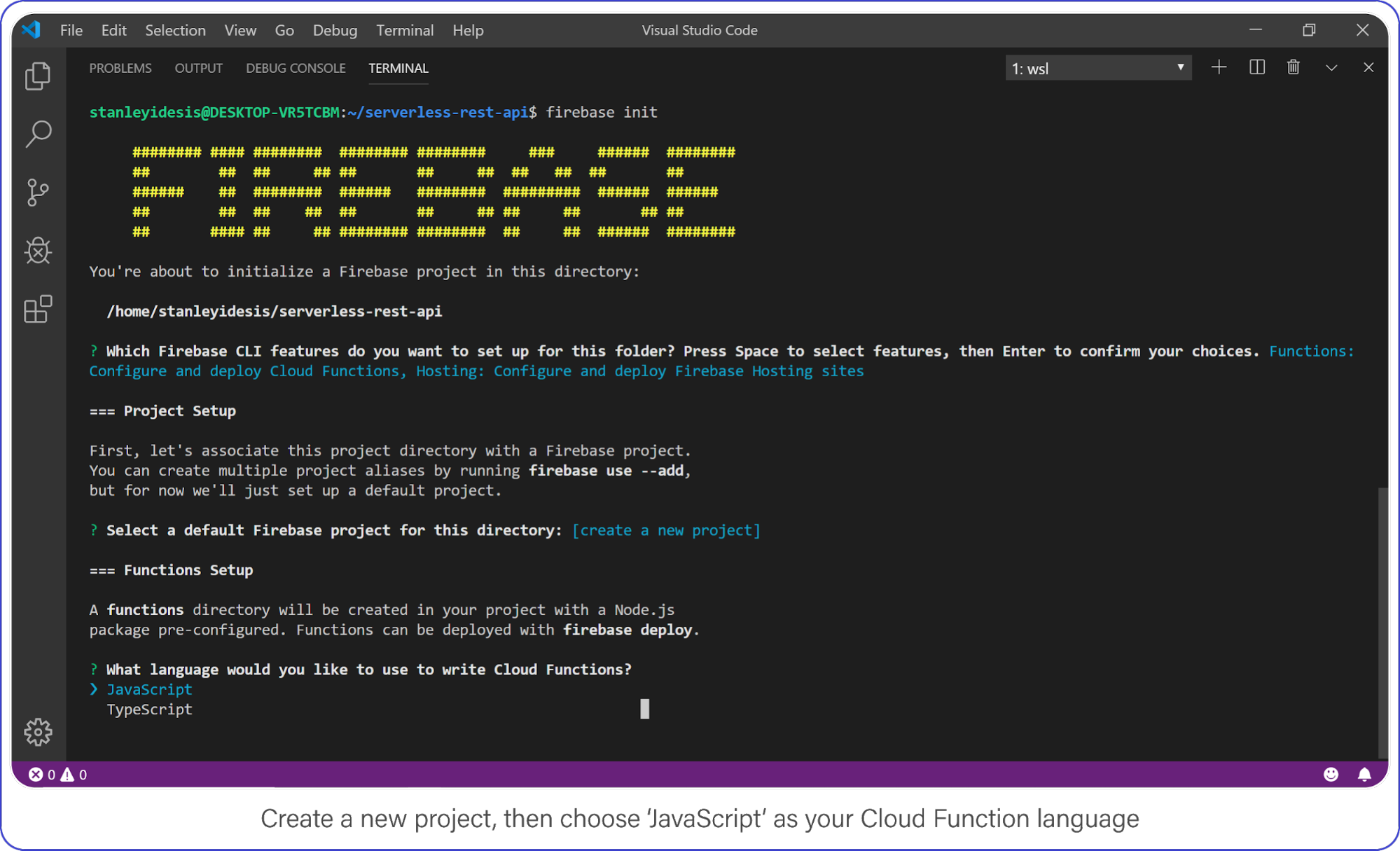
Choose "functions" and "hosting" when the bubbles appear, create a brand new firebase project, select JavaScript as your language, and choose yes (y) for the remaining options.
Create a new project, then choose JavaScript as your Cloud Function language.
Once complete, enter the functions directory, this is where your code lives and where you’ll add a few NPM packages.
Your API requires Express, CORS, and FaunaDB. Install it all with the following:
$ npm i cors express faunadb
Set Up FaunaDB with NodeJS and Firebase Cloud Functions
Before you can use FaunaDB, you need to sign up for an account.
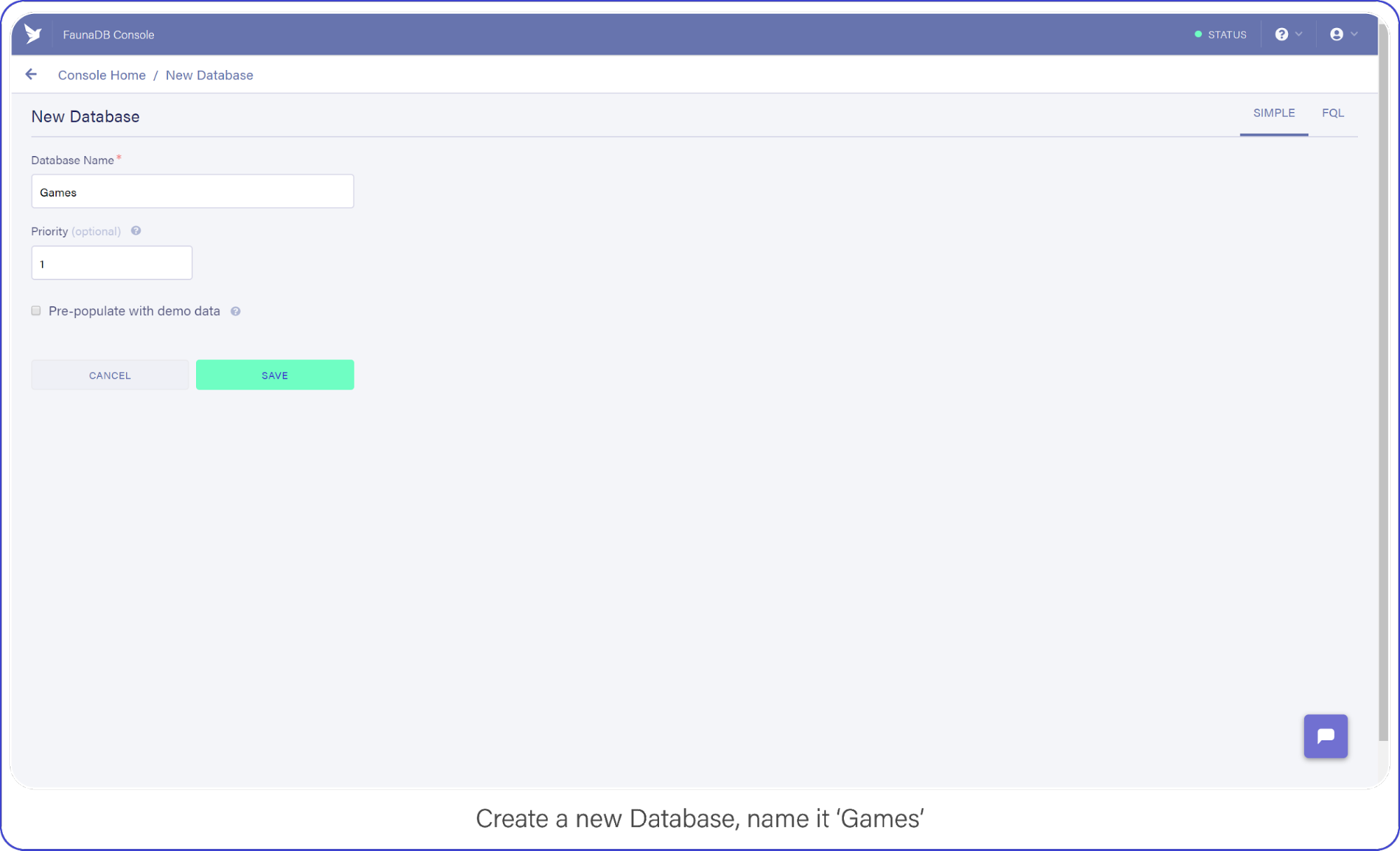
When you’re signed in, go to your FaunaDB console and create your first database, name it "Games."
You’ll notice that you can create databases inside other databases . So you could make a database for development, one for production or even make one small database per unit test suite. For now we only need ‘Games’ though, so let’s continue.
Create a new database and name it "Games."
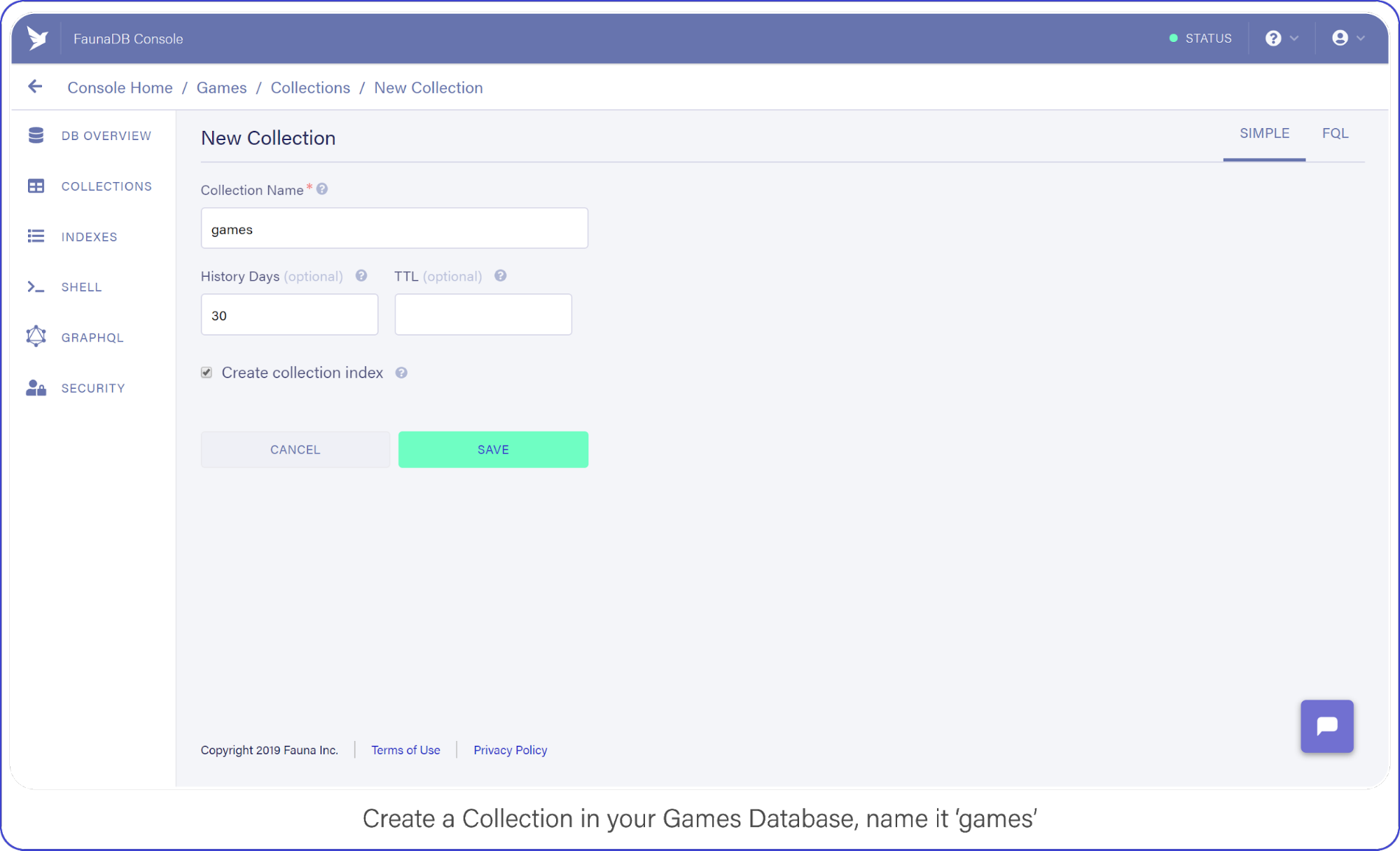
Then tab over to Collections and create your first Collection named ‘games’. Collections will contain your documents (games in this case) and are the equivalent of a table in other databases— don’t worry about payment details, Fauna has a generous free-tier, the reads and writes you perform in this tutorial will definitely not go over that free-tier. At all times you can monitor your usage in the FaunaDB console.
For the purpose of this API, make sure to name your collection ‘games’ because we’re going to be tracking your (my) favorite video games with this nerdy little API.
Create a Collection in your Games Database and name it "Games."
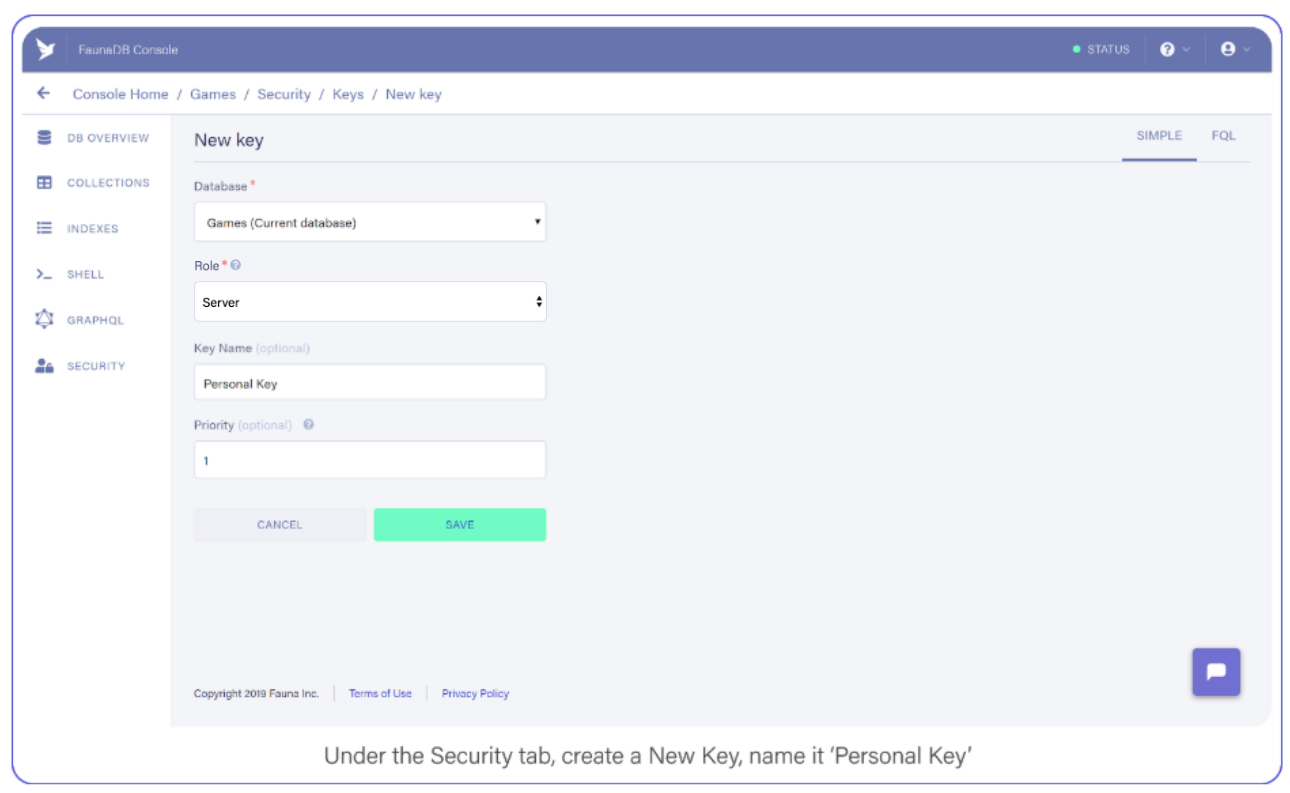
Tab over to Security, and create a new Key and name it "Personal Key." There are 3 different types of keys, Admin/Server/Client. Admin key is meant to manage multiple databases, A Server key is typically what you use in a backend which allows you to manage one database. Finally a client key is meant for untrusted clients such as your browser. Since we’ll be using this key to access one FaunaDB database in a serverless backend environment, choose ‘Server key’.
Under the Security tab, create a new Key. Name it Personal Key.
Save the key somewhere, you’ll need it shortly.
Build an Express REST API with Firebase Functions
Firebase Functions can respond directly to external HTTPS requests, and the functions pass standard Node Request and Response objects to your code — sweet. This makes Google’s Cloud Function requests accessible to middleware such as Express.
Open index.js inside your functions directory, clear out the pre-filled code, and add the following to enable Firebase Functions:
This creates a cloud function named, “api” and passes all requests directly to your api express server.
Routing an API URL to a Firebase HTTPS Cloud Function
If you deployed right now, your function’s public URL would be something like this: https://project-name.firebaseapp.com/api. That’s a clunky name for an access point if I do say so myself (and I did because I wrote this... who came up with this useless phrase?)
To remedy this predicament, you will use Firebase’s Hosting options to re-route URL globs to your new function.
Open firebase.json and add the following section immediately below the "ignore" array:
This setting assigns all /api/v1/... requests to your brand new function, making it reachable from a domain that humans won’t mind typing into their text editors.
With that, you’re ready to test your API. Your API that does... nothing!
Respond to API Requests with Express and Firebase Functions
Before you run your function locally, let’s give your API something to do.
Add this simple route to your index.js file right above your export statement:
Save your index.js fil, open up your command line, and change into the functions directory.
If you installed Firebase globally, you can run your project by entering the following: firebase serve.
This command runs both the hosting and function environments from your machine.
If Firebase is installed locally in your project directory instead, open package.json and remove the --only functions parameter from your serve command, then run npm run serve from your command line.
Visit localhost:5000/api/v1/ in your browser. If everything was set up just right, you will be greeted by a gif from one of my favorite movies.
And if it’s not one of your favorite movies too, I won’t take it personally but I will say there are other tutorials you could be reading, Bethany.
Now you can leave the hosting and functions emulator running. They will automatically update as you edit your index.js file. Neat, huh?
FaunaDB Indexing
To query data in your games collection, FaunaDB requires an Index.
Indexes generally optimize query performance across all kinds of databases, but in FaunaDB, they are mandatory and you must create them ahead of time.
As a developer just starting out with FaunaDB, this requirement felt like a digital roadblock.
"Why can’t I just query data?" I grimaced as the right side of my mouth tried to meet my eyebrow.
I had to read the documentation and become familiar with how Indexes and the Fauna Query Language (FQL) actually work; whereas Cloud Firestore creates Indexes automatically and gives me stupid-simple ways to access my data. What gives?
Typical databases just let you do what you want and if you do not stop and think: : "is this performant?" or “how much reads will this cost me?” you might have a problem in the long run. Fauna prevents this by requiring an index whenever you query.
As I created complex queries with FQL, I began to appreciate the level of understanding I had when I executed them. Whereas Firestore just gives you free candy and hopes you never ask where it came from as it abstracts away all concerns (such as performance, and more importantly: costs).
Basically, FaunaDB has the flexibility of a NoSQL database coupled with the performance attenuation one expects from a relational SQL database.
We’ll see more examples of how and why in a moment.
As with other NoSQL databases, the documents are JSON-style text blocks with the exception of a few Fauna-specific objects (such as Date used in the "release_date" field).
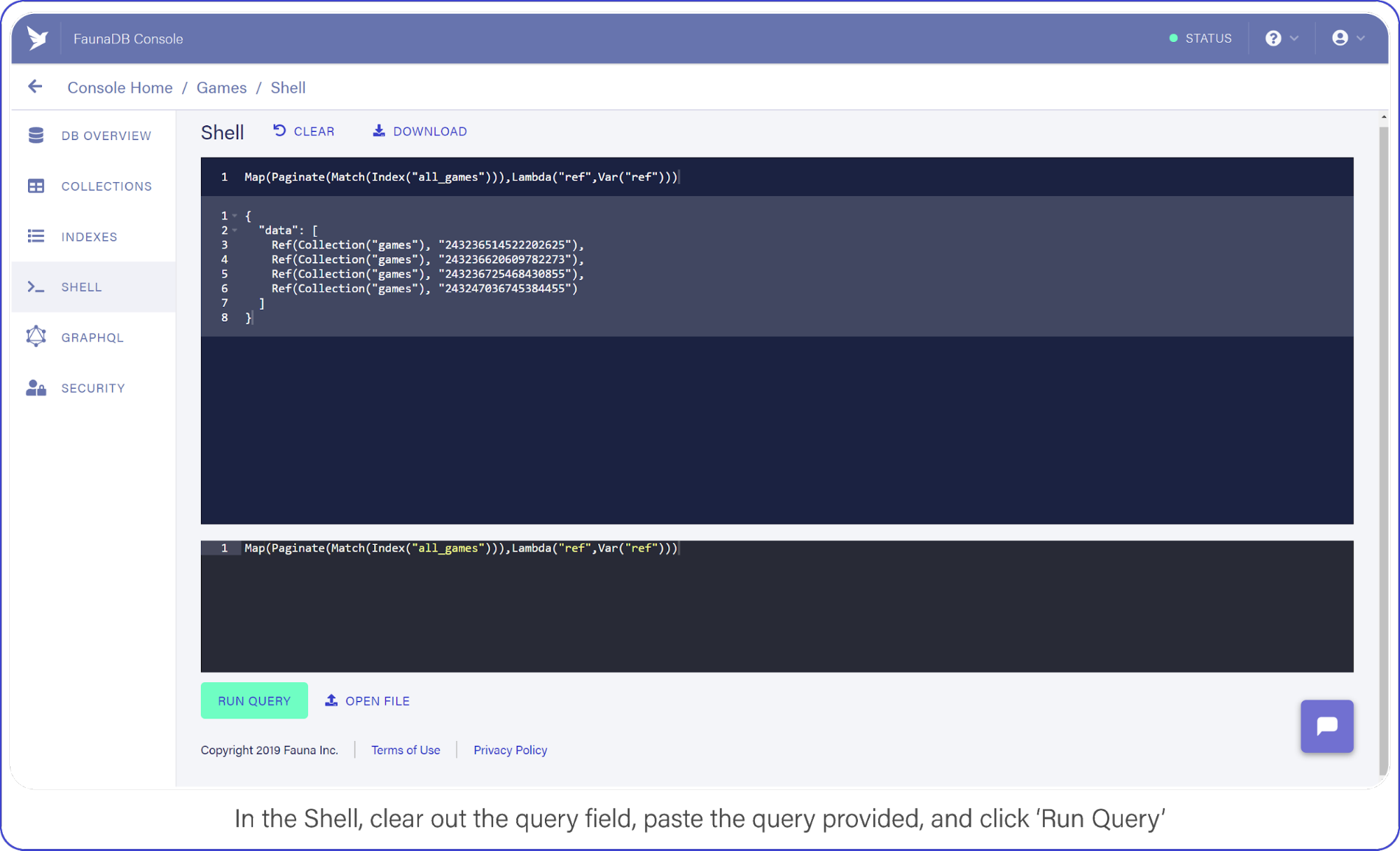
Now switch to the Shell area and clear your query. Paste the following:
And click the "Run Query" button. You should see a list of three items: references to the documents you created a moment ago.
In the Shell, clear out the query field, paste the query provided, and click "Run Query."
It’s a little long in the tooth, but here’s what the query is doing.
Index("all_games") creates a reference to the all_games index which Fauna generated automatically for you when you established your collection.These default indexes are organized by reference and return references as values. So in this case we use the Match function on the index to return a Set of references. Since we do not filter anywhere, we will receive every document in the ‘games’ collection.
The set that was returned from Match is then passed to Paginate. This function as you would expect adds pagination functionality (forward, backward, skip ahead). Lastly, you pass the result of Paginate to Map, which much like its software counterpart lets you perform an operation on each element in a Set and return an array, in this case it is simply returning ref (the reference id).
As we mentioned before, the default index only returns references. The Lambda operation that we fed to Map, pulls this ref field from each entry in the paginated set. The result is an array of references.
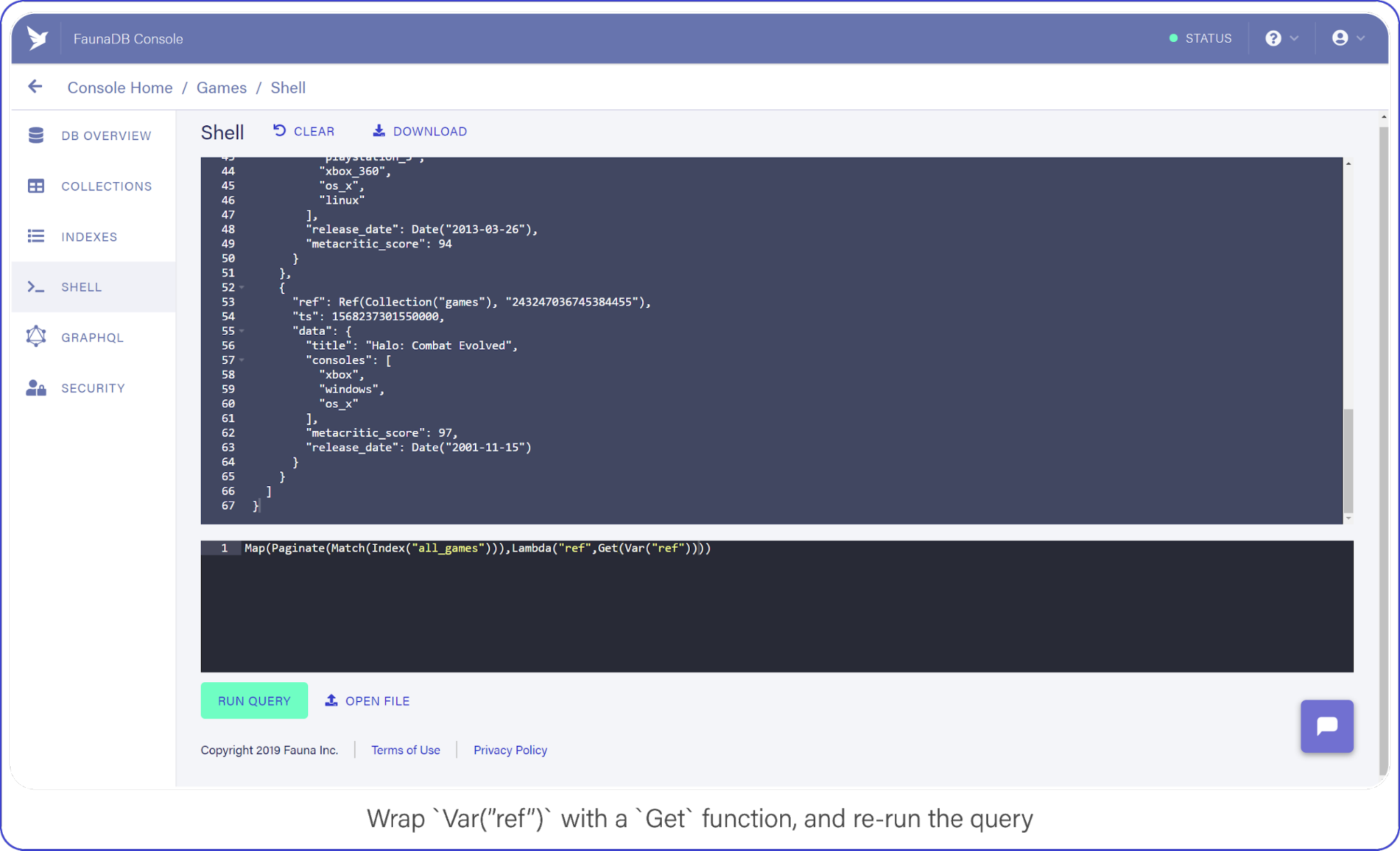
Now that you have a list of references, you can retrieve the data behind the reference by using another function: Get.
Wrap Var("ref") with a Get call and re-run your query, which should look like this:
You perform a Create, pass in your collection, and include data fields that come straight from the body of the request.
client.query returns a Promise, the success-state of which provides a reference to the newly-created document.
And to make sure it’s working, you return the reference to the caller. Let’s see it in action.
Test Firebase Functions Locally with Postman and cURL
Use Postman or cURL to make the following request against localhost:5000/api/v1/ to add Halo: Combat Evolved to your list of games (or whichever Halo is your favorite but absolutely not 4, 5, Reach, Wars, Wars 2, Spartan...)
If everything went right, you should see a reference coming back with your request and a new document show up in your FaunaDB console.
Now that you have some data in your games collection, let’s learn how to retrieve it.
Retrieve FaunaDB Records Using a REST API Request
Earlier, I mentioned that every FaunaDB query requires an Index and that Fauna prevents you from doing inefficient queries. Since our next query will return games filtered by a game console, we can’t simply use a traditional `where` clause since that might be inefficient without an index. In Fauna, we first need to define an index that allows us to filter.
To filter, we need to specify which terms we want to filter on. And by terms, I mean the fields of document you expect to search on.
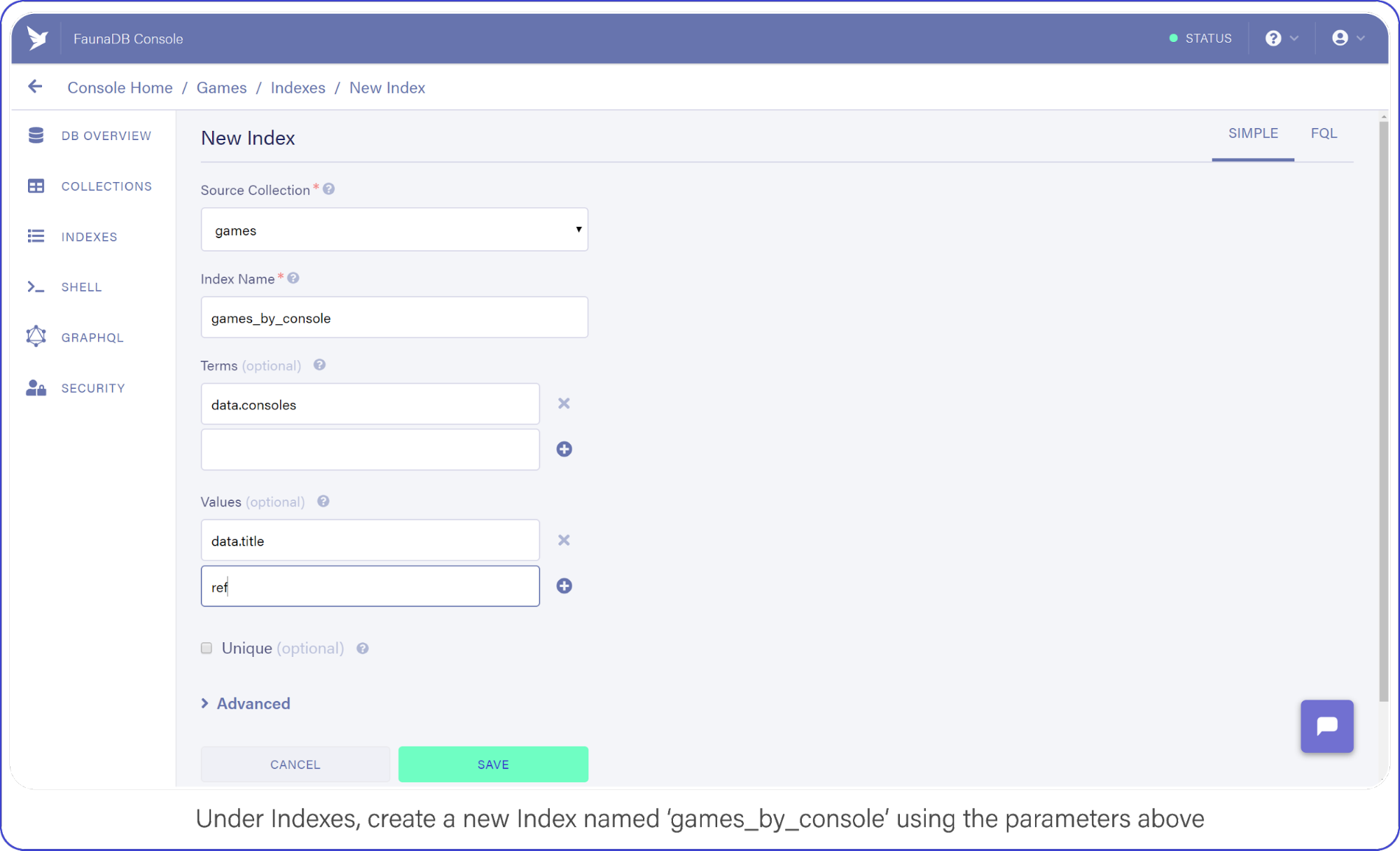
Navigate to Indexes in your FaunaDB Console and create a new one.
Name it games_by_console, set data.consoles as the only term since we will filter on the consoles. Then set data.title and ref as values. Values are indexed by range, but they are also just the values that will be returned by the query. Indexes are in that sense a bit like views, you can create an index that returns a different combination of fields and each index can have different security.
To minimize request overhead, we’ve limited the response data (e.g. values) to titles and the reference.
Your screen should resemble this one:
Under indexes, create a new index named games_by_console using the parameters above.
Click "Save" when you’re ready.
With your Index prepared, you can draft up your next API call.
I chose to represent consoles as a directory path where the console identifier is the sole parameter, e.g. /api/v1/console/playstation_3, not necessarily best practice, but not the worst either — come on now.
This query looks similar to the one you used in your SHELL to retrieve all games, but with a slight modification.This query looks similar to the one you used in your SHELL to retrieve all games, but with a slight modification. Note how your Match function now has a second parameter (req.params.name.toLowerCase()) which is the console identifier that was passed in through the URL.
The Index you made a moment ago, games_by_console, had one Term in it (the consoles array), this corresponds to the parameter we have provided to the match parameter. Basically, the Match function searches for the string you pass as its second argument in the index. The next interesting bit is the Lambda function. Your first encounter with Lamba featured a single string as Lambda’s first argument, “ref.”
However, the games_by_console Index returns two fields per result, the two values you specified earlier when you created the Index (data.title and ref). So basically we receive a paginated set containing tuples of titles and references, but we only need titles. In case your set contains multiple values, the parameter of your lambda will be an array. The array parameter above (`['title', 'ref']`) says that the first value is bound to the text variable title and the second is bound to the variable ref. text parameter. These variables can then be retrieved again further in the query by using Var(‘title’). In this case, both “title” and “ref,” were returned by the index and your Map with Lambda function maps over this list of results and simply returns only the list of titles for each game.
In fauna, the composition of queries happens before they are executed. When you write var q = q.Match(q.Index('games_by_console'))), the variable just contains a query but no query was executed yet. Only when you pass the query to client.query(q) to be executed, it will execute. You can even pass javascript variables in other Fauna FQL functions to start composing queries. his is a big benefit of querying in Fauna vs the chained asynchronous queries required of Firestore. If you ever have tried to generate very complex queries in SQL dynamically, then you will also appreciate the composition and less declarative nature of FQL.
Neat, huh? But Match only returns documents whose fields are exact matches, which doesn’t help the user looking for a game whose title they can barely recall.
Although Fauna does not offer fuzzy searching via indexes (yet), we can provide similar functionality by making an index on all words in the string. Or if we want really flexible fuzzy searching we can use the filter syntax. Note that its is not necessarily a good idea from a performance or cost point of view… but hey, we’ll do it because we can and because it is a great example of how flexible FQL is!
Filtering FaunaDB Documents by Search String
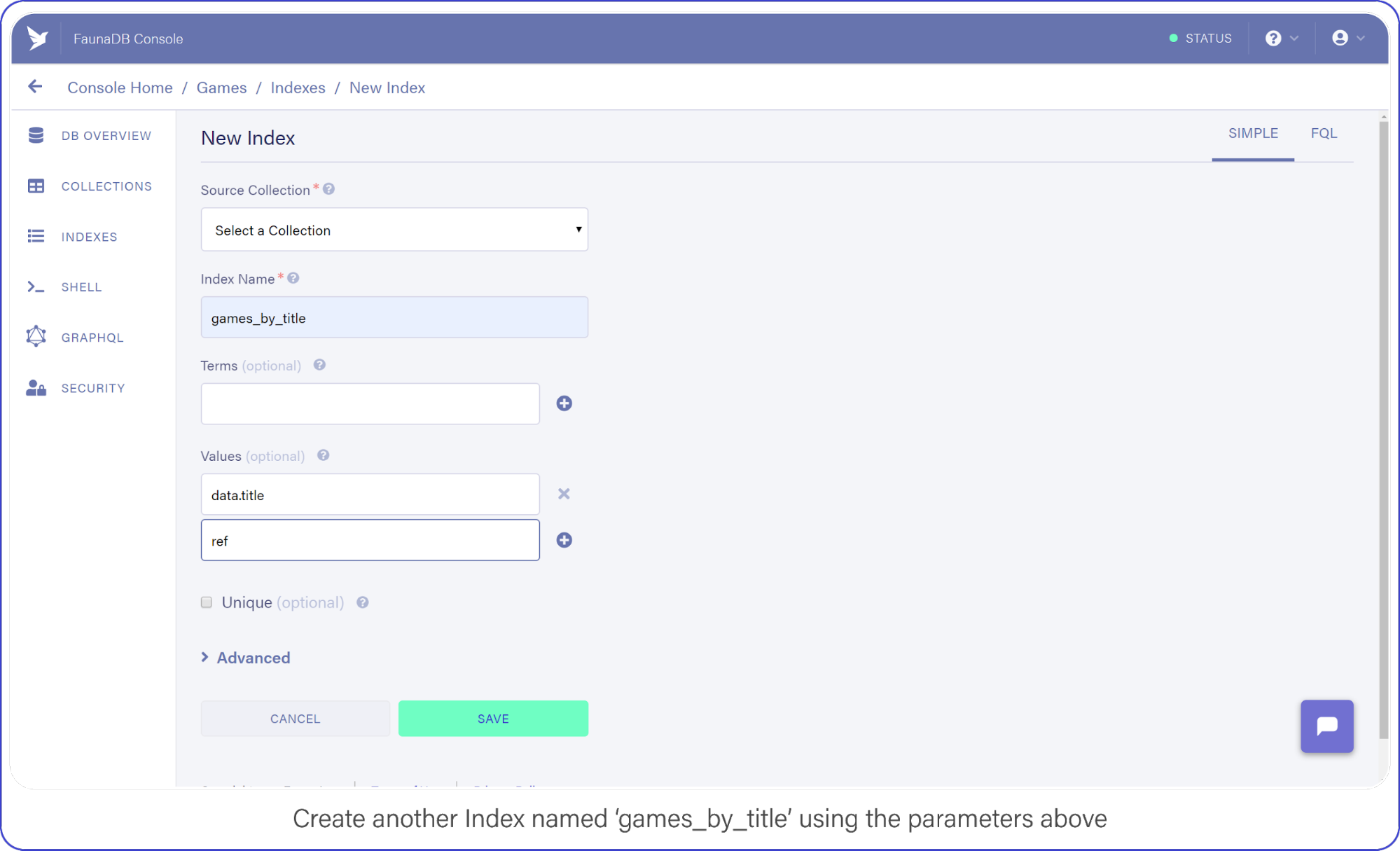
The last API call we are going to construct will let users find titles by name. Head back into your FaunaDB Console, select INDEXES and click NEW INDEX. Name the new Index, games_by_title and leave the Terms empty, you won’t be needing them.
Rather than rely on Match to compare the title to the search string, you will iterate over every game in your collection to find titles that contain the search query.
Remember how we mentioned that indexes are a bit like views. In order to filter on title , we need to include `data.title` as a value returned by the Index. Since we are using Filter on the results of Match, we have to make sure that Match returns the title so we can work with it.
Add data.title and ref as Values, compare your screen to mine:
Create another index called games_by_title using the parameters above.
Click "Save" when you’re ready.
Back in index.js, add your fourth and final API call:
Big breath because I know there are many brackets (Lisp programmers will love this) , but once you understand the components, the full query is quite easy to understand since it’s basically just like coding.
Beginning with the first new function you spot, Filter. Filter is again very similar to the filter you encounter in programming languages. It reduces an Array or Set to a subset based on the result of a Lambda function.
In this Filter, you exclude any game titles that do not contain the user’s search query.
You do that by comparing the result of FindStr (a string finding function similar to JavaScript’s indexOf) to -1, a non-negative value here means FindStr discovered the user’s query in a lowercase-version of the game’s title.
And the result of this Filter is passed to Map, where each document is retrieved and placed in the final result output.
Now you may have thought the obvious: performing a string comparison across four entries is cheap, 2 million…? Not so much.
This is an inefficient way to perform a text search, but it will get the job done for the purpose of this example. (Maybe we should have used ElasticSearch or Solr for this?) Well in that case, FaunaDB is quite perfect as central system to keep your data safe and feed this data into a search engine thanks to the temporal aspect which allows you to ask Fauna: “Hey, give me the last changes since timestamp X?”. So you could setup ElasticSearch next to it and use FaunaDB (soon they have push messages) to update it whenever there are changes. Whoever did this once knows how hard it is to keep such an external search up to date and correct, FaunaDB makes it quite easy.
Don’t You Dare Forget This One Firebase Optimization
A lot of Firebase Cloud Functions code snippets make one terribly wrong assumption: that each function invocation is independent of another.
In reality, Firebase Function instances can remain "hot" for a short period of time, prepared to execute subsequent requests.
This means you should lazy-load your variables and cache the results to help reduce computation time (and money!) during peak activity, here’s how:
let functions, admin, faunadb, q, client, express, cors, api
if (typeof api === 'undefined') {
... // dump the existing code here
}
exports.api = functions.https.onRequest(api)
Deploy Your REST API with Firebase Functions
Finally, deploy both your functions and hosting configuration to Firebase by running firebase deploy from your shell.
Without a custom domain name, refer to your Firebase subdomain when making API requests, e.g. https://{project-name}.firebaseapp.com/api/v1/.
What Next?
FaunaDB has made me a conscientious developer.
When using other schemaless databases, I start off with great intentions by treating documents as if I instantiated them with a DDL (strict types, version numbers, the whole shebang).
While that keeps me organized for a short while, soon after standards fall in favor of speed and my documents splinter: leaving outdated formatting and zombie data behind.
By forcing me to think about how I query my data, which Indexes I need, and how to best manipulate that data before it returns to my server, I remain conscious of my documents.
To aid me in remaining forever organized, my catalog (in FaunaDB Console) of Indexes helps me keep track of everything my documents offer.
And by incorporating this wide range of arithmetic and linguistic functions right into the query language, FaunaDB encourages me to maximize efficiency and keep a close eye on my data-storage policies. Considering the affordable pricing model, I’d sooner run 10k+ data manipulations on FaunaDB’s servers than on a single Cloud Function.
So much care and planning has gone into creating the web platform, to ensure that even as new features are added, they’re added in a way that doesn’t break the web for anyone using an older device or browser. Can you say the same for any framework out there? I don’t mean that to be perceived as throwing shade (as the kids say). Building the actual web platform requires a deeper level of commitment to these sorts of things out of necessity.
The platform (meaning using standard features built into browsers) might not have everything you need (it often won't) and using those features will bring long-term resiliency to what you build in a way that a framework may not. The web evolves and very likely won't break things. Frameworks evolve and very likely will break things.
CSS allows you to create dynamic layouts and interfaces on the web, but as a language, it is static: once a value is set, it cannot be changed. The idea of randomness is off the table. Generating random numbers at runtime is the territory of JavaScript, not so much CSS. Or is it? If we factor in a little user interaction, we actually can generate some degree of randomness in CSS. Let’s take a look!
Randomization from other languages
There are ways to get some "dynamic randomization" using CSS variables as Robin Rendle explains in an article on CSS-Tricks. But these solutions are not 100% CSS, as they require JavaScript to update the CSS variable with the new random value.
We can use preprocessors such as Sass or Less to generate random values, but once the CSS code is compiled and exported, the values are fixed and the randomness is lost. As Jake Albaugh explains:
random in sass is like randomly choosing the name of a main character in a story. it's only random when written. it doesn't change.
In the past, I've developed simple CSS-only apps such as a trivia game, a Simon game, and a magic trick. But I wanted to do something a little bit more complicated. I'll leave a discussion about the validity, utility, or practicality of creating these CSS-only snippets for a later time.
Based on the premise that some board games could be represented as Finite State Machines (FSM), they could be represented using HTML and CSS. So I started developing a game of Snakes and Ladders (aka Chutes and Ladders). It is a simple game. The goal is to advance a pawn from the beginning to the end of the board by avoiding the snakes and trying to go up the ladders.
The project seemed feasible, but there was something that I was missing: rolling dice!
The roll of dice (along with the flip of a coin) are universally recognized for randomization. You roll the dice or flip the coin, and you get an unknown value each time.
Simulating a random dice roll
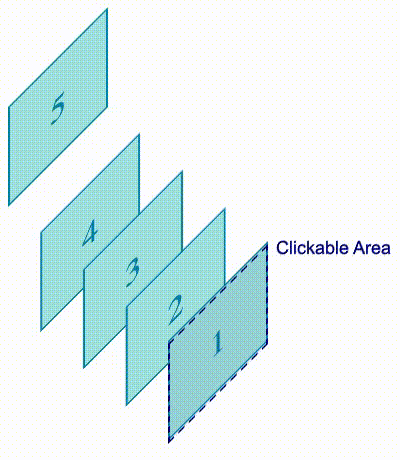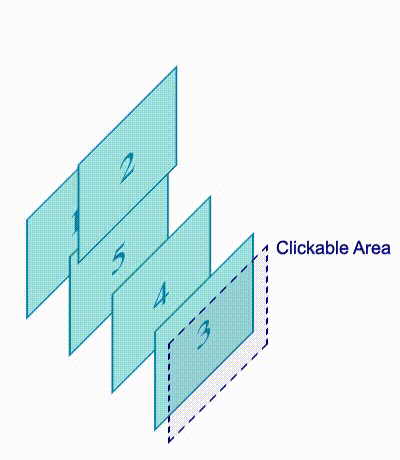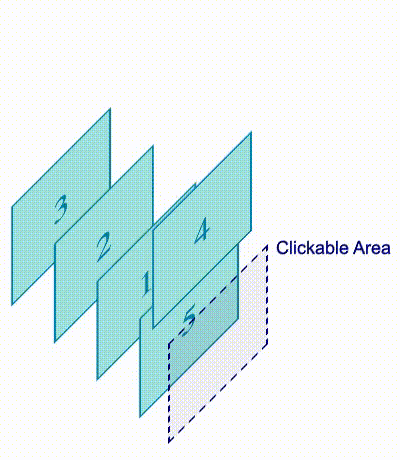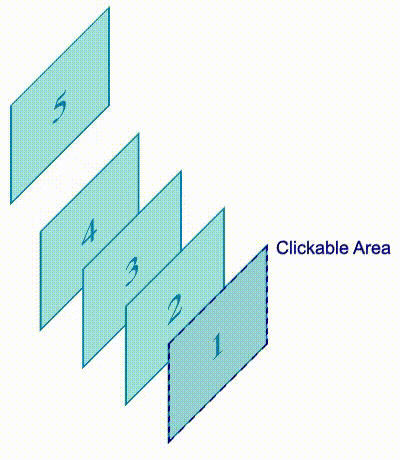
I was going to superimpose layers with labels, and use CSS animations to "rotate" and exchange which layer was on top. Something like this:
Simulation of how the layers animate on a browser
The code to mimic this randomization is not excessively complicated and can be achieved with an animation and different animation delays:
/* The highest z-index is the numbers of sides in the dice */
@keyframes changeOrder {
from { z-index: 6; }
to { z-index: 1; }
}
/* All the labels overlap by using absolute positioning */
label {
animation: changeOrder 3s infinite linear;
background: #ddd;
cursor: pointer;
display: block;
left: 1rem;
padding: 1rem;
position: absolute;
top: 1rem;
user-select: none;
}
/* Negative delay so all parts of the animation are in motion */
label:nth-of-type(1) { animation-delay: -0.0s; }
label:nth-of-type(2) { animation-delay: -0.5s; }
label:nth-of-type(3) { animation-delay: -1.0s; }
label:nth-of-type(4) { animation-delay: -1.5s; }
label:nth-of-type(5) { animation-delay: -2.0s; }
label:nth-of-type(6) { animation-delay: -2.5s; }
The animation has been slowed down to allow easier interaction (but still fast enough to see the roadblock explained below). The pseudo-randomness is clearer, too.
But then I hit a roadblock: I was getting random numbers, but sometimes, even when I was clicking on my "dice," it was not returning any value.
I tried increasing the times in the animation, and that seemed to help a bit, but I was still having some unexpected values.
That's when I did what most developers do when they find a roadblock they cannot resolve just by searching online: I asked other developers for help in the form of a StackOverflow question.
To simplify a little, the problem was that the browser only triggers the click/press event when the element that is active on mouse down is the same element that is active on mouse up.
Because of the rotating animation, the top label on mouse down was not the top label on mouse up, unless I did it fast or slow enough for the animation to circle around. That's why increasing the animation times hid these issues.
The solution was to apply a position of "static" to break the stacking context, and use a pseudo-element like ::before or ::after with a higher z-index to occupy its place. This way, the active label would always be on top when the mouse went up.
/* The active tag will be static and moved out of the window */
label:active {
margin-left: 200%;
position: static;
}
/* A pseudo-element of the label occupies all the space with a higher z-index */
label:active::before {
content: "";
position: absolute;
top: 0;
right: 0;
left: 0;
bottom: 0;
z-index: 10;
}
Here is the code with the solution with a faster animation time:
After making this change, the one thing left was to create a small interface to draw a fake dice to click, and the CSS Snakes and Ladders was completed.
This technique has some obvious inconveniences
It requires user input: a label must be clicked to trigger the "random number generation."
It doesn't scale well: it works great with small sets of values, but it is a pain for large ranges.
It’s not really random, but pseudo-random: a computer could easily detect which value would be generated in each moment.
But on the other hand, it is 100% CSS (no need for preprocessors or other external helpers) and, for a human user, it can look 100% random.
And talking about hands... This method can be used not only for random numbers but for random anything. In this case, we used it to "randomly" pick the computer choice in a Rock-Paper-Scissors game:
Accessibility is our job. We hear it all the time. But the truth is that it often takes a back seat to competing priorities, deadlines, and decisions from above. How can we solve that?
That's where An Event Apart comes in. Making sites inclusive by design is just one of the many topics covered over three full days of sessions designed to inspire you and level up your skills while learning from 17 of today's most talented front-end professionals.
And at An Event Apart, you don’t just learn from the best, you interact with them — at lunch, between sessions, and at the famous first-night Happy Hour party. Web design is more challenging than ever. Attend An Event Apart to be ready for anything the industry throws at you.
CSS-Tricks readers save $100 off any two or three days with code AEACP.
It’s a wonder that Echo Buds didn’t arrive sooner. Earbuds (I still can’t write “hearables” without cringing a bit) are the clearest path to making Alexa work outside of the home. Amazon, after all, has been unable to crack the smartphone category. Half a decade later, the Fire Phone is little more than a historical curiosity, while Google and Apple have had massive mobile footprints to spread their smart assistants.
Amazon has dabbled in mobile, with a downloadable Alexa app and Fire Tablet functionality. Last year, the company announced the Alexa Mobile Accessory Kit, which is designed to bring the AI to more devices. Certainly it makes sense as a third-party partner for companies that don’t have the resources or desire to develop their own assistant. The latest Fitbit Versa might be the best example of such an alliance.
From a pure user experience standpoint, however, headphones are the most logical conduit. They’re positioned closest to the mouth for voice commands via microphone and, obviously, offer a direct route into the ear for Alexa responses. In waiting to see how the market shakes out, the company has ceded potential market share.
There’s a lot about the Echo Buds that would have made them an excellent addition to the category two or three years ago. But the category is among the fastest moving in consumer electronics. Samsung, Sony and Apple/Beats all have excellent offerings, and Amazon opening up Alexa to hardware companies has all but assured that third-party products from companies will eclipse the Echo Buds shortly.
The company does get some things right on its first go. If there’s one thing the Echo Buds really have going for them, it’s customization. For the earbuds themselves, that means not only the customary replaceable silicone tips, but also wings to help them stay in place in the ear. I’ve never been a fan of the hard plastic wings, but the soft silicone covers that slip over the buds are a nice touch.
They’re available in three sizes, so you should be able to find a decent fit. Once everything is in place, the buds should form a nice seal to keep sound in and unwanted ambient noise out. For my money, though, the PowerBeats Pro are still the best on the market when it comes to fit. The over-the-ear design keeps them from straining your ears after an extended period. Amazon’s solution is fairly elegant, as well.
The rest of the customization — and just about everything else, for that matter — is done in the app. Without its own operating system, the Echo Buds don’t have quite the same out of the box pairing experience as first-party Apple or Android headphones. That said, once you’ve downloaded the app, pairing is painless. For those who have other Echo devices, there’s probably something to be said for having all of your Echo devices in a single spot.
From here, you can customize the touch gestures. By default, a double tap on the left or right ear toggles between active noise reduction (not full-on cancelation) and pass-through modes, while pressing and holding fires up Alexa. The nice thing about this is the ability to reduce accidental triggers. That’s probably my biggest complaint with the Galaxy Buds — the slightest adjustment triggers the touch. The app also offers a built-in equalizer, with sliders for bass, mid and treble, along with a five-level slider for the pass-through ambient mode.
The sound isn’t bad for the price, once you’ve got a nice seal and a the settings to your liking. Sony’s spring to mind both for the quality of the audio and the active noise canceling, but they’re priced at nearly double Amazon’s. I suppose we’ll be able to compare it to Apple’s in the near future, but again, pricing is a major consideration. I like the idea of pass through mode more than the actual implementation. The concept is a nice one — the ability to let in your surroundings. The ambient sound feature leans a little too heavily on the microphones. I wouldn’t recommend having it anywhere above a one out of four. Things like an AC unit were amplified to a point that was overwhelming.
Alexa, meanwhile, is still very much a home assistant, but Amazon should be building upon that as it makes a more aggressive push. This early implementation was a little buggy in the first go. Asking for the news, Alexa had trouble connecting to NPR, and instead just gave me the weather. Trying to get the assistant to fire up noise reduction with my took a couple of goes, but in both cases, I eventually got them to work. On a whole, however, the microphone did a good job recognizing commands.
The design of the buds themselves is fairly generic, but that’s perfectly fine. The charging case, meanwhile, is a pretty reasonable size, somewhere between the AirPods’ little dental floss case and the massive PowerBeats Pros. It’s small enough to carry around in your pocket — one of my biggest issues with Beats’ otherwise terrific earbuds. The materials are certainly on the cheap size, and the inclusion of a microUSB slot in 2019 certainly gives the industry of a company working hard to keep prices down.
At $130, they’re priced $30 less than the standard AirPods 2. Amazon would have done well to go all in on pricing here — $99 would have been a really solid sweet spot for the company — well below other premium earbuds. That’s still a decent premium over off-brand buds, but a familiar name — and assistant — would surely carry some weight with Amazon shoppers. And given that much of the market has settled at between $150 and $250, they’re a downright deal by comparison.
Amazon will almost certainly sell plenty, and knowing Amazon, we may see some decent discounts around the holidays. And hey, with Apple’s recent announcement of $249 AirPod Pros, that $130 price tag just got a whole lot more appealing.
from Amazon – TechCrunch https://ift.tt/2MTYP4X
via IFTTT
Amazon is turning up the heat once again in the world of groceries, and specifically grocery delivery, to make its service more enticing in face of competition from Walmart, as well as a host of delivery companies like Postmates. Today, the company announced that it would make Amazon Fresh — the fresh food delivery service it now offers in some 2,000 cities in the US and elsewhere — free to use for Prime members, removing the $14.99/month fee that it was charging for the service up to now.
Alongside free delivery, Amazon is giving users one and two-hour delivery options for quicker turnarounds, and it’s making users’ local Whole Foods inventory available online and through the Amazon app.
Prime members who were already using Amazon’s grocery delivery services — either for Amazon’s own-branded service or to get Amazon-owned Whole Foods shopping delivered — will continue to get these, now free. Prime members who might be interested in trying this out for the first time will have to sign up here and wait for an invite. (“Given the rapid growth of grocery delivery we expect this will be a popular benefit,” Amazon explained about the waitlist.)
“Prime members love the convenience of free grocery delivery on Amazon, which is why we’ve made Amazon Fresh a free benefit of Prime, saving customers $14.99 per month,” said Stephenie Landry, VP of Grocery Delivery, in a statement. “Grocery delivery is one of the fastest growing businesses at Amazon, and we think this will be one of the most-loved Prime benefits.”
Making Amazon Fresh free is the latest price tinkering (and reduction) that Amazon has made to drive more usage of the grocery service, while at the same time expanding the sweeteners it gives to consumers to sign up to Prime. The $14.99/month fee was introduced back in 2016, itself a reduction on a $299/year fee that Amazon previously charged Amazon Fresh customers. Before that, Amazon charged a $99/year subscription plus separate delivery fees to use the service.
It’s not clear how many customers are already using Amazon Fresh, or whether the service is profitable not for the company at this point. Notably, despite the boost of Amazon owning the Whole Foods chain of supermarkets, analysts earlier this year estimated that while Amazon was still seeing its grocery service growing, that growth was slowing. (To add to that, we’ve seen some consolidations that point to Amazon looking for ways to simplify — and reduce the cost — of its grocery shopping offering.)
Despite all this, in the US, about a year ago it was estimated in a separate report that Amazon accounted for about one-third of all grocery delivery in the US.
Grocery delivery is a tricky business, much more perishable than delivering a book or a piece of clothing or a piece of consumer electronics, but it represents, if done right, a frequently recurring line of revenue. Too add to that, Amazon has made fast and free delivery one of the major cornerstones of how it grows its business and attracts customers away from using other online shopping options, or visiting actual brick-and-mortar stores.
In other words, regardless of whether it is profitable or not, it makes sense that Amazon would invest in ways of trying to boost its grocery delivery service, making it free being perhaps the biggest boost yet (next stop: cash back when you use it?). It fits with the company’s more general economies-of scale approach: bring in more users buying more groceries, and make up the margins in the latter to offset potential losses in the former, which is now a fully-fledged loss leader in the company’s business.
But the move to make deliveries “free” — free, that is, for those who are already paying $12.99/month or $119/year for Amazon Prime — is a classic Amazon move not just to boost its own usage numbers of the service.
The company is facing persistent competition from a number of other companies also providing online grocery shopping and delivery. In the UK, just about every large grocery chain offers this service directly (or through another non-Amazon partner). And in the US, Walmart announced just last month that it would be expanding its $98/year Delivery Unlimited service, which up until today would have been a cheaper deal than Amazon’s. Both Postmates and Doordash are among the delivery hopefuls who also have ambitions to make a dent in this area.
from Amazon – TechCrunch https://ift.tt/32YfQ3E
via IFTTT
Best I could tell from the last time I compiled the most wished-for features of CSS, styling form controls was a major ask. Top 5, I'd say. And of the native form elements that people want to style, Greg Whitworth has some data that the <select> element is more requested than any other element — more than double the next element — and it's the one developers most often customize in some way.
Developers clearly want to style select dropdowns.
You actually do a little. Perhaps more than you realize.
Notably, this is an entirely cross-browser solution. It's not something limited to only the most progressive desktop browsers. There are some visual differences across browsers and platforms, but overall it's pretty consistent and gives you a baseline from which to further customize it.
That's just the "outside"
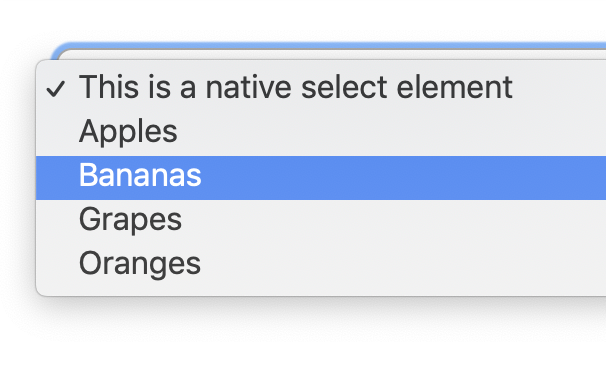
Open the select. Hmm, it looks and behaves like you did nothing to it at all.
Styling a <select> doesn't do anything to the opened dropdown of items. (Screenshot from macOS Chrome)
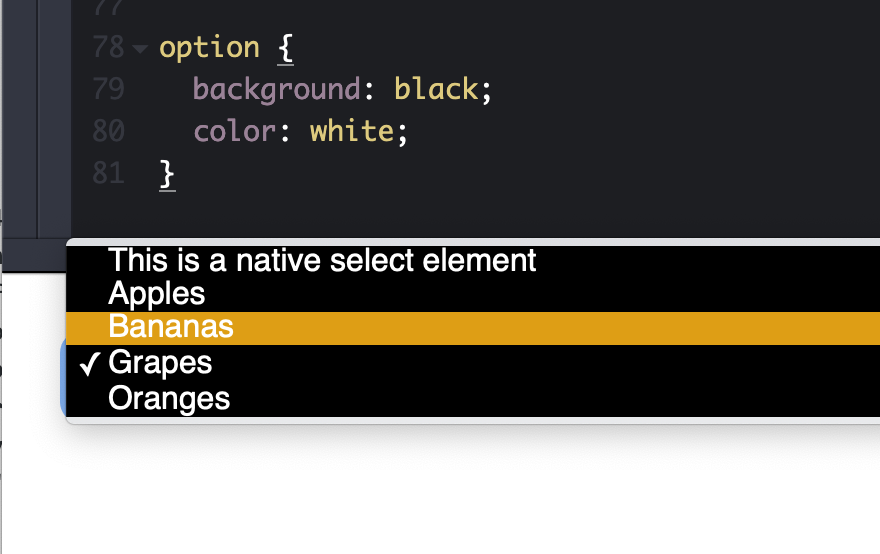
Some browsers do let you style the inside, but it's very limited. Any time I've gone down this road, I've had a bad time getting things cross-browser compliant.
Firefox letting me set the background of the dropdown and the color of a hovered option.
Greg's data shows that only 14% (third place) of developers found styling the outside to be the most painful part of select elements. I'm gonna steal his chart because it's absolutely fascinating:
Frustration
%
Count
Not being able to create a good user experience for searching within the list
27.43%
186
Not being able to style the <option> element to the extent that you needed to
17.85%
121
Not being able to style the default state (dropdown arrow, etc.)
14.01%
95
Not being able to style the pop-up window on desktop (e.g. the border, drop shadows, etc.)
11.36%
77
Insertion of content beyond simple text in the <select> control or its <option>s
11.21%
76
Insertion of arbitrary HTML content in an <option> element
7.82%
53
Not being able to create distinctive unselected/placeholder style and behavior
3.39%
23
Being able to generate new options from a large dataset while the popup is open
3.10%
21
Not being able to style the currently selected <option>(s) to the extent you needed to
1.77%
12
Not being able to style the pop-up window on mobile
1.03%
7
Being able to have the options automatically repeat on scroll (i.e., if you have an list of options 1 – 100, as you reach 100 rather than having the user scroll back to the top, have 1 show up below 100)
1.03%
7
Boiled down, the most painful parts of styling selects are:
Search
Styling the open dropdown, including the individual options, including more than just text
Updating the element without closing it
Styling for cases where "nothing" is selected and when an item is selected
I'm surprised multi-select didn't make the cut. Maybe it's not on the table for <select> since it wouldn't be backwards-compatible?
Browser evolution
Edge recently announced they are improving the look of form controls, but no word just yet on standards or how to customize them.
Select styles in Edge/Chromium before (left) and after (right)
It seems like there is good momentum, though. If you want more information and to follow along with all this progress (I know I will!):
Our weekly round-up of what’s going on in space technology is back, and it’s a big one (and a day late) because last week was the annual International Astronautical Congress. I was on the ground in Washington, D.C. for this year’s event, and it’s fair to say that the top-of-mind topics were 1) Public-private partnerships on future space exploration; 2) So-called ‘Old Space’ or established companies vs./collaborating with so-called ‘New Space’ or younger companies, and 3) who will own and control space as it becomes a resource trough, and through what mechanisms.
There’s a lot to unpack there, and I plan to do so not all at once, but through conversations and coverage to follow. In the meantime, here’s just a taste based on the highlights from my perspective at the show.
SpaceX timelines are basically just incredibly optimistic dreams, but it’s still worth paying attention to what timeframes the company is theoretically marching towards, because they do at least provide some kind of baseline from which to extrapolate actual timelines based on past performance.
There’s a reason SpaceX wants to send its newest there that early, however – beyond being aggressive to motivate the team. The goal is to use that demonstration mission to set up actual cargo transportation flights, to get stuff to the lunar surface ahead of NASA’s planned 2024 human landing.
More SpaceX news, but significant because it could herald the beginning of a new era where the biggest broadband providers are satellite constellation operators. SpaceX COO and President Gwynne Shotwell says that the company’s Starlink broadband service should go live for consumers next year. Elon also used it this week to send a tweet, so it’s working in some capacity already.
Bridenstine did a lot of speaking and press opportunities at IAC this year, which makes sense since it’s the first time the U.S. has hosted the show in many years. But I managed to get one question in, and the NASA Administrator detailed how he sees entrepreneurs contributing to his ambitious goal of returning to the Moon (this time to set up a more or less permanent presence) by 2024.
Virgin Galactic listed itself on the New York Stock Exchange today, and we got our very first taste of what public market investors think about space tourism and commercial human spaceflight. So far, looks like they… approve? Stock is trading up about 2 percent as of this writing, at least.
Amazon CEO Jeff Bezos got a first-ever IAC industry award during the show (it has an actual name but it seems pretty clear it’s an invention designed to fish billionaire space magnates to the stage). The award is fine, but the actual news is that Blue Origin is teaming up with space frenemies Lockheed Martin, Northrop Grumman and Draper – old and new space partnering to develop a full-featured lunar lander system to help get payloads to the surface of the Moon.
Launch startup Rocket Lab has become noteworthy for being among the extremely elite group of new space companies that is actually launching payloads to orbit for paying customers. It wants to do more, of course, and one of its new goals is to adapt its Photon payload delivery spacecraft to bring customer satellites and research equipment to the Moon – and eventually beyond, too. Why? Customer demand, according to Rocket Lab CEO Peter Beck.
It seems like there’s a lot of space startup activity the world over, but Europe has possibly more than its fair share, thanks in part to the very encouraging efforts of the multinational European Space Agency. (Extra Crunch subscription required.)
from Amazon – TechCrunch https://ift.tt/2q2W8Vv
via IFTTT
The DoD JEDI contract saga came to a thrilling conclusion on Friday afternoon, appropriately enough, with one final plot twist. The presumptive favorite, Amazon did not win, stunning many, including likely the company itself. In the end, Microsoft took home the $10 billion prize.
This contract was filled with drama from the beginning, given the amount of money involved, the length of the contract, the winner-take-all nature of the deal — and the politics. We can’t forget the politics. This was Washington after all and Jeff Bezos does own the Washington Post.
Then there was Oracle’s fury throughout the procurement process. The president got involved in August. The current defense secretary recused himself on Wednesday, two days before the decision came down. It was all just so much drama, even the final decision itself, handed down late Friday afternoon, but it’s unclear if this is the end or just another twist in this ongoing tale.
Before we get too crazy about Microsoft getting a $10 billion, 10 year contract, consider that Amazon earned $9 billion last quarter alone in cloud revenue. Microsoft reported $33 billion last quarter in total revenue. It reported around $11 billion in cloud revenue. Synergy Research pegs the current cloud infrastructure market at well over $100 billion annually (and growing).
What we have here is a contract that’s worth a billion a year. What’s more, it’s possible it might not even be worth that much if the government uses one of its out clauses. The deal is actually initially guaranteed for just two years. Then there are a couple of three-year options, with a final two-year option at the end if gets that far.
The DOD recognized that with the unique nature of this contract, going with a single vendor, it wanted to keep its options open should the tech world shift suddenly under its feet. It didn’t want to be inextricably tied to one company for a decade if that company was suddenly disrupted by someone else. Given the shifting sands of technology, that part of the strategy was a wise one.
If value of this deal was not the contract itself, it begs the question, why did everyone want it so badly? The $10 billion JEDI deal was simply a point of entree. If you could modernize the DoD’s infrastructure, the argument goes, chances are you could do the same for other areas of the government. It could open the door for Microsoft for a much more lucrative government cloud business.
But it’s not as though Microsoft didn’t already have a lucrative cloud business. In 2016, for example, the company signed a deal worth almost a billion dollars to help move the entire department to Windows 10. Amazon too, has had its share of government contracts, famously landing the $600 million to build the CIA’s private cloud.
But given all the attention to this deal, it always felt a little different from your standard government contract. Just the fact the DoD used a Star Wars reference for the project acronym drew more attention to the project from the start. Therefore, there was some prestige for the winner of this deal, and Microsoft gets bragging rights this morning, while Amazon is left to ponder what the heck happened. As for other companies like Oracle, who knows how they’re feeling about this outcome.
Ah yes Oracle; this tale would not be complete without discussing the rage of Oracle throughout the JEDI RFP process. Even before the RFP process started, they were complaining about the procurement process. Co-CEO Safra Catz had dinner with the president to complain that contract process wasn’t fair (not fair!). Then it tried complaining to the Government Accountability Office. They found no issue with the process.
They went to court. The judge dismissed their claims that involved both the procurement process and that a former Amazon employee, who was hired by DoD, was involved in the process of creating the RFP. They claimed that the former employee was proof that the deal was tilted toward Amazon. The judge disagreed and dismissed their complaints.
What Oracle could never admit, was that it simply didn’t have the same cloud chops that Microsoft and Amazon, the two finalists, had. It couldn’t be that they were late to the cloud or had a fraction of the market share that Amazon and Microsoft had. It had to be the process or that someone was boxing them out.
Outside of the politics of this decision (which we will get to shortly), Microsoft brought some experience and tooling the table that certainly gave it some advantage in the selection process. Until we see the reasons for the selections, it’s hard to know exactly why DoD chose Microsoft, but we know a few things.
First of all there are the existing contracts with DoD, including the aforementioned Windows 10 contract and a five year $1.76 billion contract with DoD Intelligence to provide “innovative enterprise services” to the DoD.
Then there is Azure Stack, a portable private cloud stack that the military could stand up anywhere. It could have great utility for missions in the field when communicating with a cloud server could be problematic.
So that’s that right? The decision has been made and it’s time to move on. Amazon will go home and lick its wounds. Microsoft gets bragging rights and we’re good. Actually, this might not be where it ends at all.
Amazon for instance could point to Jim Mattis’ book where he wrote that the president told the then Defense Secretary to “screw Bezos out of that $10 billion contract.” Mattis says he refused saying he would go by the book, but it certainly leaves the door open to a conflict question.
It’s also worth pointing out that Jeff Bezos owns the Washington Post and the president isn’t exactly in love with that particular publication. In fact, this week, the White House canceled its subscription and encouraged other government agencies to do so as well.
Then there is the matter of current Defense Secretary Mark Espers suddenly recusing himself last Wednesday afternoon based on a minor point that one of his adult children works at IBM (in a non-cloud consulting job). He claimed he wanted to remove any hint of conflict of interest, but at this point in the process, it was down to Microsoft and Amazon. IBM wasn’t even involved.
If Amazon wanted to protest this decision, it seems it would have much more solid ground to do so than Oracle ever had.
The bottom line is a decision has been made, at least for now, but this process has been rife with controversy from the start, just by the design of the project, so it wouldn’t be surprising to see Amazon take some protest action of its own. It seems oddly appropriate.